
Nuances of Working with Redis. Part 1
Exploring aspects of effectively leveraging and applying Redis
12/1/202316 min read


What is Redis?
Redis is an in-memory database that is well-suited for the following purposes:
Caching data: This scenario is suitable when there is a key that allows you to read or write cache. A common case is using Redis as a cache in front of another "persistent" database like MySQL.
Storing sessions: This scenario is suitable as a project grows, when we get multiple application instances on different machines behind a load balancer, and there is a need to store user sessions in storage that is accessible to every application server.
Pub/Sub: In addition to a data store, Redis can be used as a message broker. In this case, a publisher can publish messages to a named channel for any number of subscribers. When a client publishes a message to a channel, Redis delivers this message to all clients subscribed to that channel, enabling real-time information exchange between individual application components. However, it is important to remember that this message is published in a fire & forget pattern - the sender sends the message without expecting explicit confirmation from the recipient that the message has been received. That is, there is no delivery guarantee, and if some subscribers lose the connection, then after returning they will not receive the missed messages. And if there are no recipients at all, then the message is lost without the possibility of recovery.
We will not dwell on other possible uses of Redis, as well as on basic aspects, and will move on to the features of its operation that directly affect configuration and efficiency:
Single-threaded
This is both an advantage and a disadvantage at the same time: due to the sequential execution of commands, we by definition do not get problems with concurrency and locks. Only one command is executed at any one time, all others are queued up and executed in the order they arrived, in one thread. However, if the database receives a non-optimal query that will take a long time, for example associated with a full scan of keys, Redis is actually blocked: until the heavy query completes, all other queries line up in the queue and typically return the best results accumulated at that point by timeout, or an error - depending on the policy set using ON_TIMEOUT.
Eviction policies
Redis has a mechanism for deleting outdated keys when adding new data, called eviction. It is implemented through the maxmemory parameter, which sets the limit after which the key deletion process begins. In general, the sequence of actions inside Redis looks like this:
A client launches a command to add new data;
Before executing the command, Redis checks if memory usage exceeds the maxmemory parameter;
If memory usage exceeds the maxmemory parameter, a group of keys is deleted. The eviction policy specified in the maxmemory-policy parameter is used for deletion (more on this below);
After deleting old keys, the command is executed and new keys are added.
If you set the maxmemory value to 0, then Redis has no memory limit. In 64-bit systems, the value is set to 0 by default, and for 32-bit architectures the system implicitly uses a maximum memory limit of 3Gb.
The eviction policy sets the rules for how Redis deletes a key when it reaches the memory limit specified in the maxmemory parameter. If no key matches the policy criteria or the maxmemory-policy parameter is set to noeviction, then no key will be evicted. Instead, the Redis server will return errors for all write operations and only respond to read commands such as GET, effectively switching to read only mode. We can get acquainted with the main eviction policies on the official Redis website.
It is important to understand that eviction is also a process that runs in the main thread along with processing client requests. When Redis reaches its maxmemory threshold, it frees up memory by deleting keys to get back below the maxmemory value. If your Redis gets a number of keys in one transaction that exceeds maxmemory, they will still end up in Redis, and the eviction process will start after the transaction completes. In the example below, we loaded 100,000,000 10-byte keys with a maxmemory parameter of 10485760:
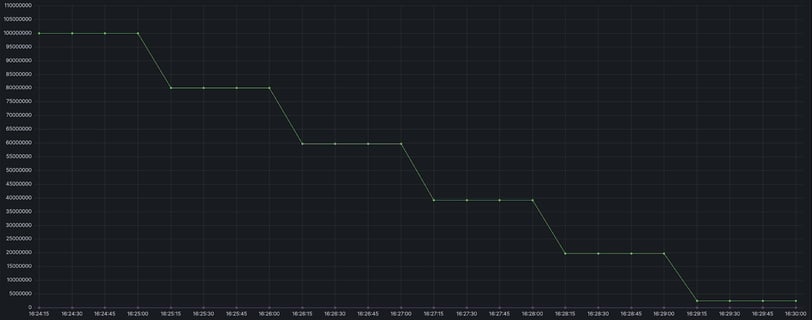
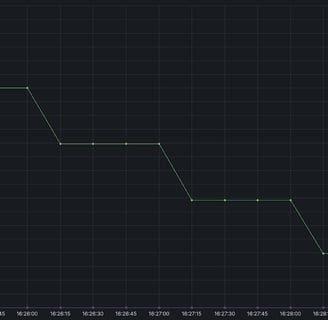
At the same time, memory consumption exceeded the established maxmemory limits and eviction began only after the transaction was completed:
Note: the Redis transactions mentioned above do not work the same as for example in ACID databases. After receiving a sequence of atomic commands, Redis starts executing them in a queue created earlier in the order in which they entered the queue, during execution the transaction occupies the main thread. An error during the execution of any of the commands in the transaction interrupts the transaction, but does not cause a rollback: the result of executing previous commands within the transaction is not canceled.
From the graph above, another detail is also noticeable: the eviction process is not one continuous operation, but a series of iterative ones, while limited to one time frame. The duration of one eviction is determined by the maxmemory-eviction-tenacity parameter. By default, it is equal to 10, which is about 50 microseconds. When increasing this parameter, the eviction duration increases by 15% compared to the previous value, and when setting maxmemory-eviction-tenacity to a value of 100, the iteration time limit actually disappears. Sometimes it can be useful to reduce this parameter to make the eviction operation take up more actual time, but less main thread time, by increasing the number of iterations.
It is also worth noting that deleting keys during eviction is a blocking operation, that is, Redis stops processing new commands in order to synchronously free up all the memory associated with the deleted object. However, we can configure eviction in a non-blocking asynchronous way, by enabling the lazyfree-lazy-eviction parameter:
lazyfree-lazy-eviction yes
With the enabled parameter, memory release during eviction goes in a separate thread and the keys are actually disconnected from the key space, and their actual deletion occurs later, asynchronously.
For eviction, Redis uses 2 main algorithms: approximate LRU and LFU algorithms. The LRU algorithm is based on the assumption that if a key has been accessed recently, there is a higher probability of re-accessing it in the near future, since access patterns to keys usually do not change abruptly. In this context, the LRU algorithm tries to exclude the least used keys from the Redis cache. To implement this policy, Redis uses a field (hereinafter - the lru field), 24 bits (3 octets) in size, which tracks when the key was last used. They contain the lowest bits of the current Unix time in seconds and require 194 days to overflow - the key metadata is updated frequently, so this time is more than enough. To clear memory, Redis uses an eviction pool, which is a linked list, the pool size is rigidly set at the code level and is equal to 16 keys. This pool is filled with a sample of N keys, the first key in the pool has the least time since it was last used, and the last one has the most. After filling the eviction candidates, Redis will select the most suitable key from the end of the pool, delete it, and repeat the process until memory is freed. If there are several elements with the same timestamp, eviction occurs on a FIFO basis - the one that got into the pool earlier is deleted. Subsequent keys falling into the eviction pool will be inserted into the right position according to their timestamp, new keys fall into the pool only if their downtime is greater than that of the key from the pool or if there is free space in the pool. The number N of keys in the sample to check (and, accordingly, the accuracy of the algorithm) for each eviction can be configured using the maxmemory-samples parameter (more on this parameter below).
LFU (Least Frequently Used) is Redis's second main eviction algorithm, which is based on the idea that the keys that are most likely to be accessed in the future are the keys that are most frequently accessed overall, not the ones that were last accessed. We have 24 bits of total space in each object, because we reuse the lru field for this purpose. These 24 bits are divided into two fields, the first is an 8 bit logarithmic counter that gives an idea of how often an item is accessed. This is a function that increments the counter when keys are accessed, but the larger the counter value, the less likely it is that the counter will actually increase further. At default settings we get approximately the following:
After 100 accesses to the key, the counter value will be 10;
After 1k - 18;
After 100k - 142;
After 1 million accesses, the counter value reaches the limit of 255 and no longer increases;
However, if at one point in time there were many accesses to the key, which actually spun up its counter, then there is a chance that what used to be a frequently used key will remain so forever, and we want the algorithm to adapt to this. For this, the remaining 16 bits are used to store the "decrement time" - the Unix time converted to minutes. When Redis performs a random sample for eviction, all encountered keys are checked for the time of the last decrement. If the last decrement was performed more than N minutes ago (N is configurable via the lfu-decay-time parameter), then depending on how many times the elapsed time is greater than N, the counter is halved and the decrement time is decreased or only the decrement time is decreased. That is, over time, the counters are decreased. In order for new keys to have a chance to stay, their initial LFU counter value is 5, which gives them some time to accumulate accesses.
Since the LRU and LFU algorithms in Redis are not accurate but approximate, they can be tuned for both speed and accuracy through the maxmemory-samples parameter, which was mentioned earlier. By default, it is equal to 5, increasing it to 10 proportionally increases the accuracy of the algorithm, but increases the load on the CPU. Accordingly, lowering increases speed but reduces targeting accuracy.
Data Types
Redis uses many data types, but I would like to highlight a few. But first, it is worth noting one, at first glance, obvious point that, in our experience, developers forget over and over again: Redis works fast as long as commands with time complexity O(1) and O(log_N) are used. As soon as you decide to use a command with O(N) complexity, be prepared for load spikes if the operation involves a large number of keys.
Strings - the simplest data type. Values can be strings of any kind, for example, an image in JPEG format can be stored inside a value. The string size cannot exceed 512Mb. Most string operations are performed in O(1). It seems all simple, but there is a nuance: strings in Redis are implemented through the SDS library, in which the structure consists of a header that stores the current size and free space in the already allocated memory, the string data itself and the terminating zero value added by Redis itself.
+--------+-------------------------------+-----------+
| Header | Binary safe C alike string... | Null term |
+--------+-------------------------------+-----------+
|
-> Pointer returned to the user.
That is, to store a string we need:
an integer to denote length;
an integer to denote the number of remaining free bytes;
string;
null character.
This leads us to an important conclusion: we will be very interested in the costs of overhead data, so as not to waste extra bytes. In the often cited example, if a string has overhead data of about 90 bytes, then when executing the set foo bar command, about 96 bytes will be used, of which 90 bytes will be overhead. From this we can deduce that for maximum resource utilization, short strings, like names, email addresses, phone numbers, etc., are best placed in hashes, but more on that later.
Lists are collections of strings ordered by addition order. Redis uses linked lists internally - each element contains pointers to the previous and next elements, as well as a pointer to the string inside the element. This means that regardless of the number of elements inside the list, the operation of adding a new element to the beginning or end of the list is performed in O(1), since to insert you only need to change the links. It should also be remembered that commands that manipulate elements in the list (like LSET) usually have O(n) complexity, which can cause performance problems with a large number of elements. The maximum length of the Redis list is 4,294,967,295 elements.
Sets are an unordered collection of unique elements that is effectively suited for tracking unique components, as well as for set operations. The maximum size is 4,294,967,295 elements, most set operations are performed in O(1).
Hashes are records structured as field-value pair collections. Each hash can store up to 4,294,967,295 field-value pairs, most Redis hash commands have O(1) complexity and most importantly: hashes can be very efficiently encoded in memory (but more on that below). One of the most popular memory saving recommendations when using Redis is to use hashes instead of plain strings. If we take 1,000,000 keys in the form of "123456789", then in the form of strings they will occupy about 56Mb:
127.0.0.1:6379> flushall
OK
127.0.0.1:6379> info memory
used_memory:2441696
used_memory_human:2.33M
127.0.0.1:6379> eval "for i=0,1000000,1 do redis.call('set', i, 123456789) end" 0
127.0.0.1:6379> info memory
used_memory:58830624
used_memory_human:56.11M
At the same time, when saving data to a hash table, memory consumption was about 14Mb:
127.0.0.1:6379> flushall
OK
127.0.0.1:6379> info memory
# Memory
used_memory:2442112
used_memory_human:2.33M
127.0.0.1:6379> eval "for i=0,1000000,1 do local bucket=math.floor(i/500); redis.call('hset', bucket, i, 123456789) end" 0
(nil)
(3.02s)
127.0.0.1:6379> info memory
# Memory
used_memory:14801296
used_memory_human:14.12M
The difference is 42Mb, not bad. The situation becomes more clear when the number of integer keys grows from 1,000,000 to 100,000,000:
127.0.0.1:6379> eval "for i=0,100000000,1 do redis.call('set', i, 123456789) end" 0
(nil)
(313.34s)
127.0.0.1:6379> info memory
# Memory
used_memory:6668210336
used_memory_human:6.21G
127.0.0.1:6379> eval "for i=0,100000000,1 do local bucket=math.floor(i/500); redis.call('hset', bucket, i, 123456789) end" 0
(nil)
(307.42s)
127.0.0.1:6379> info memory
# Memory
used_memory:1242900056
used_memory_human:1.16G
Where does this memory difference come from? It's all because of Ziplist - a specially encoded doubly linked list that is designed to be extremely memory efficient. This is achieved by sequential packing of elements, in which elements are stored one after another. If the data size is small (it has few elements with small values and they are less than the threshold set by the -max-listpack- parameter), then Redis encodes it in Ziplist, which makes it very memory efficient, but affects CPU consumption .
In Redis, 6 Ziplist operation parameters are presented (parameters from Redis >= 7.0), for now let's look at 2:
list-max-ziplist-entries (default - 512) - efficiently encodes a list if its size does not exceed the set value. Otherwise, Redis automatically converts it to regular encoding.
list-max-ziplist-value (default - 64) - efficiently encodes a list if the size of the largest element in the list does not exceed the set value, otherwise Redis automatically converts it to regular encoding and saves it as a standard data type.
Let's go back to the list structure. It is easy to notice that for one element there is a need for:
three pointers (previous value, next value, string inside the list element);
two integers (length and remaining bytes);
string;
additional byte;
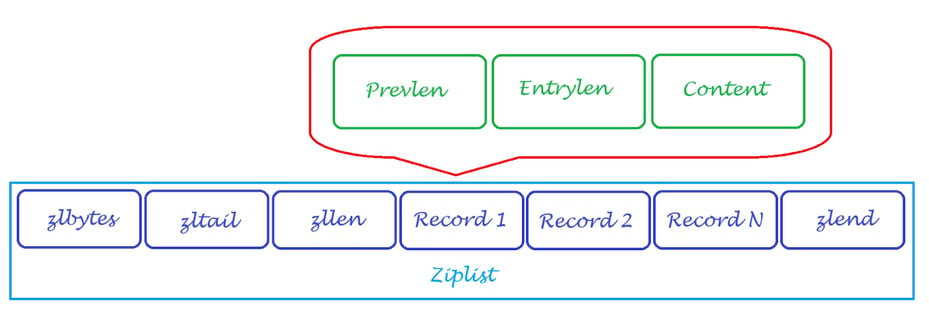
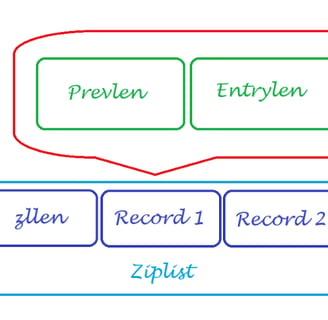
Which causes overhead costs. Ziplist represents elements as:
length of previous entry (Prevlen) to find previous item in memory;
encoding that stores the data type of the current entry (integer or string) and if it is a string, then the payload length of the string (Entrylen or encoding) is added to the stored data;
string that stores data (Content).
Sometimes Entrylen is the entry itself, for example, for small integers, and then the Content field is not needed. The size of the Prevlen field can only be represented in two values: 1 byte as an unsigned 8-bit integer if the length of the previous entry is less than 254 bytes and 5 bytes if the length is greater than or equal to 254. In this case, the first byte is set to the value 254 (FE) to indicate that a larger value follows. The remaining 4 bytes take the length of the previous entry as the value.
The content of the Entrylen field is determined by the data type of the element content: if the entry is a string, then the first 2 bits of the first byte of Entrylen will contain the encoding type used to store the string length, followed by the actual string length. If the entry is an integer, then the first two bits are set to 1. The next two bits are used to indicate which integer will be stored after this header.
And what, you ask, are there no overhead costs in Ziplist? There are, but they are fixed and extremely small:
zlbytes - an unsigned 32-bit integer containing the number of bytes occupied by the ziplist. Allows you to change the size of the entire structure without traversing the entire structure;
zltail - an unsigned 32-bit integer containing the offset to the last entry in the list. Allows you to perform a pop operation at the far end of the list without a full traversal;
zllen - an unsigned 16-bit integer containing the number of entries;
zlend - one byte equal to 255, signaling the end of ziplist. No other entry starts with a byte set to 255.
Schematically, all of the above can be depicted approximately like this:
This allows ziplist to reduce memory consumption by an order of magnitude. Similar settings exist for other data types:
hash-max-listpack-entries 512
hash-max-listpack-value 64
zset-max-listpack-entries 128
zset-max-listpack-value 64
In the example above, we used the default settings hash-max-listpack-entries = 512 and hash-max-listpack-value = 64. If we change them to 0, we get the following memory consumption with similar keys:
127.0.0.1:6379> flushall
OK
127.0.0.1:6379> eval "for i=0,100000000,1 do local bucket=math.floor(i/500); redis.call('hset', bucket, i, 123456789) end" 0
(nil)
(91.96s)
127.0.0.1:6379> info memory
# Memory
used_memory:6435185176
used_memory_human:5.99G
As you can see, the write speed of the keys has increased due to the lack of encoding, but the amount of memory occupied by the keys has grown from 1.16Gb to 5.99Gb.
Data Storage
A fundamental difference between Redis and, for example, Memcached is Redis's ability to store information on disk, which protects it from loss during emergency instance reboots or other unforeseen situations. Why do you need it? For example, if you use an In-memory cache, you will have to reload the data in case of database failure, and this process can take quite a long time. Redis offers 2 main options:
RDB is a snapshot of the data at a point in time. This is a compact backup that can be transferred not only between instances, but also, as a rule, between different versions of Redis. However, RDB provides a snapshot of the data at a point in time and does not take into account subsequent changes in the system after its creation;
AOF sequentially records each operation received by the server into a file. Compared to RDB, AOF saves all changes. It is also nice that the AOF log is intended only for writing and Redis does not change the already written data, but only appends them to the end, which, on the other hand, affects the size of the AOF log.
We will not describe in detail the advantages and disadvantages of each data storage method, because there is a lot of information on this topic on the Internet, but we will highlight a couple of nuances:
A very common mistake for a Redis novice when moving or copying an instance is to load the RDB dump from the old instance into the /var/lib/redis directory before shutting down the new instance. As a result, after restarting, Redis automatically saves data from RAM to disk, overwriting the previously loaded RDB file. This point may seem extremely obvious, however, during our work, we often encountered confusion on the part of customers who decided to recover from a dump on their own and repeatedly after restarting Redis got the old data set.
If your RDB dump size is greater than 10Gb, you may find that Redis is infinitely rising from it. With a little more thorough analysis, you will notice that after loading a certain amount of data into RAM, Redis reboots and the data loading process starts all over again. The problem is that by default in the Redis unit file, the TimeoutStartSec parameter responsible for startup timeout is not explicitly set. If the daemon does not signal completion of startup within the configured time, the start will be considered unsuccessful and the daemon will be shut down. By default, TimeoutStartSec is 90 seconds and if Redis does not have time to load the data into RAM during this time, Redis will be rebooted. The solution is to set the TimeoutStartSec parameter to infinity.
Try to take RDB dumps from the production database as rarely as possible if the database size is more than a few gigabytes. Fork is used in the main thread to create an RDB, which can cause noticeable latency in the Redis instance. The best solution is to set up master-slave replication and take backups from the slave.
The appendonly yes + appendfsync always parameters can cause noticeable slowing of Redis due to fsync being performed on each operation. It is better to use appendonly yes + appendfsync everysec.
From all of the above, the following recommendations for configuring Redis can be derived:
- Avoid using small strings, it is inefficient;
- Use hashes;
- Monitor key sizes;
- If your total Redis data size is less than 3Gb, consider using the 32-bit Redis version;
- Do not use keys with unlimited TTL, it is advisable to limit the TTL size to the minimum required key lifetime;
- Use the eviction policy so as not to clutter Redis and adjust the maxmemory-policy parameter depending on the structure of the database and the frequency of access to keys;
- Find values for the -max-listpack-entries and -max-listpack-value parameters at which most elements are converted to zip format. However, do not set too large a value (more than 1000) so as not to cause CPU load;
- Decrease the maxmemory-eviction-tenacity parameter to reduce the time the main thread uses for the eviction process;
- Enable the lazyfree-lazy-eviction parameter for non-blocking key eviction;
- Increase/decrease the value of the maxmemory-samples parameter depending on the requirements for accuracy/speed;
- Do not use maxmemory = 0 on 64-bit Redis builds and always limit memory consumption;
- To conveniently control or analyze the contents of Redis, use the RedisInsight utility, and also pay attention to the ANALYSE/Memory Analysis/Recommendations tab in it. It specifies recommendations for saving memory to improve application performance, memory usage analysis is performed in autonomous mode and does not affect Redis performance.
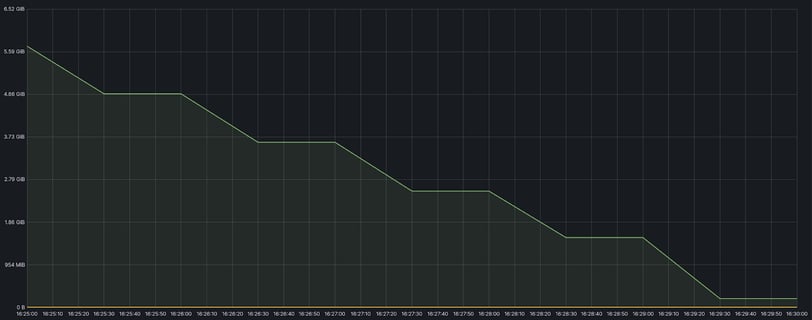
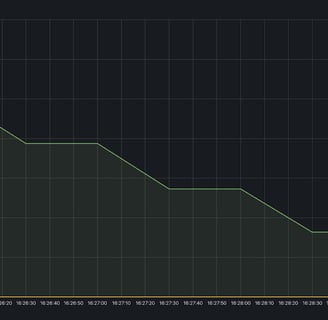
Using this advice, we were able to reduce RAM usage on a project from ~30Gb to ~15Gb:
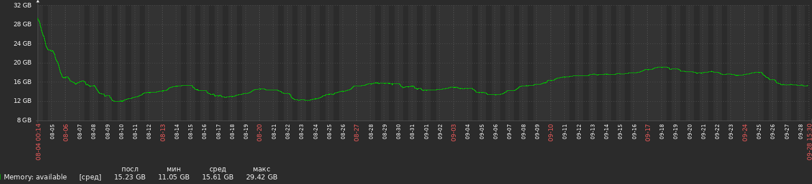
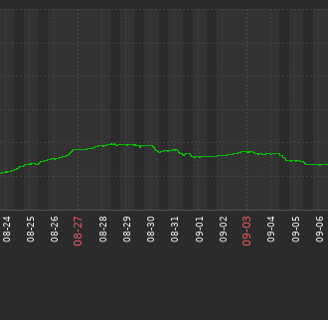
Without removing the proportional to this difference number of keys:
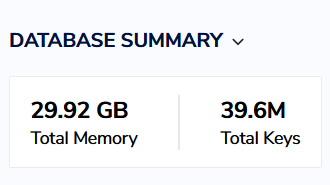
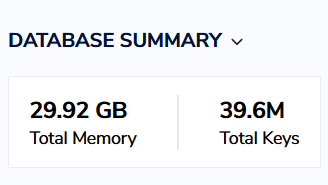
Before optimization
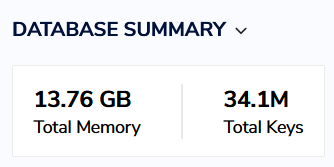
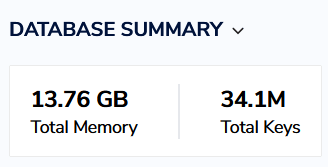
After optimization
